
Even lower down on the completion scale than the other software here, this non-project sprang into non-being after throwing around some ideas for OCR software, to help Project Gutenberg and their distributed proofreaders. I'd seen that they have a huge backlog of scanned but unconverted texts, and it seems that particularly non-English texts can be problematic. So how about an open-source OCR tool specifically for PG, to help them in their task?
It starts off of course with a scanned image of a page, and the first job is to find the page boundaries, if any, and correct the rotation. Then the contrast might need to be adjusted and maybe the image rescaled to help the following steps. Next it needs to be segmented, to chop it up into distinct paragraphs or columns. This can be done recursively to identify individual headlines, columns, paragraphs and lines. Then each segment might need to have its contrast adjusted individually, for example if a title banner is white on black instead of black on white. Here (if the image is colour) you might be able to pick particular colour channels with the best contrast, and reduce it to greyscale in a cleverer way than just using lightness.
We can illustrate this technique with a simple example. Suppose we have a scanned page as shown below. It's not perfectly aligned with the scanner so the first step is to correct this orientation. A segmentation step then follows to try to find blocks within the page. In this first step, three blocks are found - the title section, a two-column section and a final paragraph.
Page boundaries The first step is to try to identify the page boundaries and rotate the image to bring the boundaries horizontal and vertical if possible. |  | -> |  |
Page segmentation The page may consist of several segments. The next step is to try to identify these segments and extract them into separate images for further processing. Here, three blocks are identified. | | -> |  |
Segment pre-processing For each segment, there may be some pre-processing steps possible to improve the success of the recognition step. Here the contrast is low and the text is reversed, so a good possibility is to invert and stretch the levels of the image. |  | -> | 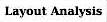 |
Segment segmentation Some segments may themselves be split into sub-segments in a recursive way. Here, the middle segment consists of two columns, which can be split and processed separately. |  | -> |  |
Subsegment segmentation Following the recursion, the paragraphs and image sections within each of the two columns can be split and passed separately to the recognition step. | | -> |   |
In this example, one of the sections contains two images. Continuing the recursion would split this segment once more into two image blocks but probably both of these images would not be able to be recognised and the contents would either be ignored or replaced by placeholders.
For each of the text blocks you can try and split into words, and then letters. Then comes the hard part with the recognition of individual letters. Ideally it should be font-independent, and shouldn't require the software to learn thousands of possible fonts. Presumably there are some very clever algorithms for extracting lines, edges, crossings and line curvatures to make a good guess what the letter is. But better would be to get a set of the top few letters it might be, and their corresponding probabilities. Then when you put them together into a word, you can use a dictionary (now language-specific) to guess what the most likely word is. Of course, possible diacritics and ligatures make the letter recognition much more difficult, even just for Latin alphabets, so maybe the language should be known in advance to reduce the number of possible letters.
Anyway, now you've got a good idea what the word might be, or a small number of possible words with their probabilities, and then you can use grammar checking (again, very language-specific) to pick a set of words which goes well into a sentence. Obviously hyphenation is then a problem when a word gets split over lines, so this would have to be resolved somehow. And of course all text has very variable justification and kerning, and may be italic or otherwise more complex to split up. And that's not even considering tables and so on.
And what's the output? Well, for Project Gutenberg they only really need the text, but of course additional output to HTML or ODT would be terrific. It may also make sense to make the recognition interactive, so it could show you the image of a word it's not sure about, and ask you to identify it, thereby doing some kind of learning.
So with all these ideas, why is this a non-project? Because of course, as I should have known, there are already many many many such projects already, with clever people who have studied this problem in incredible depth. See for example Wikipedia's list.
There are a bunch of open-source projects already, including GOCR/JOCR, Gnu Ocrad, and the big fish, Tesseract, which was bought by Google and then open-sourced. This is fairly restrictive, still apparently quite raw, and command-line only, but apparently still out-performs the other backends out there. And there are other projects such as OCRFeeder to act as a frontend, so the GUI can do the layout analysis first and then just pass on the individual segments to Tesseract. And the OCRFeeder video is quite impressive. As shown in that video, it still makes recognition mistakes even with fairly clean-looking input, but it can save the output to odt which is very useful.
Google obviously has a very keen interest in OCR anyway because of projects like Google Books and Google Goggles, and it's got the resources to put whole teams of clever people on the problem. So even though it's an extremely interesting field of work to get stuck into, it seems unreasonable to expect to be able to compete with their offerings now that they've been released.
So there seems to be a general trend to split the OCR workhorse off into a separate backend, and allow it to be called by any frontend you like. Which makes a lot of sense. So if a new project can't compete with the well-established, well-researched existing projects out there, maybe it might make sense to find out how they do things and maybe help them out improving them? Except Tesseract sounds like a complete mess as far as the code is concerned, and extracting the useful nuggets sounds very painful. The Kooka frontend seems to have died, which leaves OCRFeeder, and from the video that seems to be doing an excellent job already, so TextRactor seems to be trying to solve a problem that's already been solved. Apart from collecting and transcoding all the language-specific training data, of course.
So maybe Project Gutenberg doesn't need yet another OCR tool, maybe it just needs more volunteer proofreaders to go over the resulting texts? And just wait for Google to iron out the wrinkles in their Tesseract backend?